Class
11
Hopefully you’ve tried the tomcat install at home—problems?
Note: there is another example servlet, servlet2, on the course website. This shows you how to access a local file, needed for pa2.
Good idea to try these out first on UNIX: see directions on forum entry.
Start from pa1b solution, unless your solution is really complete.
PA2-related Notes
Idea: POX (plain old xml) servlet serving out Grid.xml, etc., XML as in pa1.
Clients receive whole XML docs, parse them and extract info they want, here a list of method names.
This is more efficient than having the client get the individual method names from the server, because in the Internet, the round-trip time is the killer of performance. Better to get a big blob of data at once, than lots of little bits.
Eclipse makes writing servlets easier, once we get it working--if you’re still having trouble with it, just use command line tools for now. We need to use this approach on UNIX anyway.
Also note that in pa2 you don't need to use a DTD or Schema for the clients--SAX and XPath work fine without these
Servlet programming/debugging Basics
Your servlet code is running in the tomcat JVM, somewhat further away than you are probably used to. What happens to standard output?
Good old println-to-System.out: in tomcat, writes to log.
In servlet1, in doGet(), see "System.out.println("in doGet");
Run it “ant deploy” then “ant test1”
Find the output "in doGet", with timestamp, in logs/localhost.2013-03-04.log
If you are using tomcat run from eclipse, you'll see the output in the Console view, a combination log.
You could write HTML or XML to out, but you would lose it in cases of serious errors, so the log is a better way.
Later, when servlet development in eclipse is familiar, try out debugging.
XML Reading
APIs - an overview (Chap. 5 surveys the parsers)
Goals for an XML parser (page 217)
o convert the stream to Unicode (though Java does this for us)
o assembling the different parts of a document divided into multiple entities (see page 25)
o resolve character references (like ߦ) and built in entities (like <)
o understand CDATA sections
o check well-formedness constraints
o keep track of namespaces and their scope
o validate the document against its DTD or Schema (not all parsers do this)
o deal with unparsed entities (like images)
o assign types to attributes (like CDATA, ID, IDREF, see list pg. 34)
A CDATA section (not to be confused with CDATA attribute type) contains text that is not parsed in any way. An example from the standard:
<![CDATA[<greeting>Hello world</greeting>]]>
<![CDATA[ is the CDStart markup for a CDATA section and ]]> is the CDEnd markup.
- The content is everything in between. it is interpreted as literal text, markup does not count
- In content for an element: <foo>blah blah <![CDATA[<greeting>Hello world</greeting>]]></foo>
- The parser delivers character content for element foo as "blah blah <greeting>Hello world</greeting>", or for XPath, this is in the text node below element node "foo".
SAX - "Simple API for XML"
· the gold standard for XML parsing
· is a read only API
· is an event driven API, this is, it uses callbacks
· lightweight - it doesn't create Java objects on its own
· the programmer has to create object if he or she needs them
· this or StAX are the only ways to deal with huge XML documents that won't fit into memory
DOM - "Document Object Model"
· the term DOM is used to refer to both the model and the API
· turns XML into a tree of objects
· can write XML, unlike SAX
· resulting DOM tree can support XPath queries, unlike SAX and STAX
· great for small or non-large documents
· can create and then update a tree of objects
· expensive in terms of memory and cpu cycles
JAXP - "Java API for XML Parsing"
· is an envelope package that manages SAX, DOM and XSLT
JDOM (we’re skipping this)
· like DOM it creates a tree of objects
· designed by Java people specifically for Java
· less ugly than DOM, which must be language neutral, in detail, but has gaps which make it less general, especially in mixed content
StAX: Streaming XML Parser, newer than our text
· Like SAX, it uses little memory, so is efficient
· Considered easier to use than SAX: support an iterator on XML, rather than callbacks
· Has an XML writer associated with it, unlike SAX.
From Sun’s Web services tutorial:
SAX programming
To use SAX you create an XMLReader object, to which you register the class you create implementing the ContentHandler interface, which have the call backs that do the work in the programs we write
Note: when we create an XMLReader object from JDK classes, we should use the no-argument version of XMLReaderFactory.createXMLReader( ), which will use the default parser, Xerces, as the parser. Xerxes is the best parser according to Harold.
NOTE: The call to createXMLReader shown on page 213 will not work on our systems--just drop the argument.
Example 5.3, pages 230 - 231, is a SAX client that has been created to read the XML generated by the XML-RPC server, shown at the top of page 142. here is the output from this server along with the events SAX generates:
C:\XMLJAVA>java FibonacciXMLRPCClient 10
<?xml
version="1.0"?> startDocument event
<methodResponse> startElement
event
<params> startElement event
<param> startElement event
<value>
startElement event
<double> startElement event <--at
this callback, set flag "inDouble"
55
characters event <--at this
callback, get the "55", knowing we're inside <double>
</double> endElement
event <--at this callback, reset
flag "inDouble"
</value>
endElement event
</param> endElement event
</params> endElement event
</methodResponse> endElement event
We want to
extract the “55” from this XML. We have
to do this by creating the right callback methods—see above ß
notes for the plan. Each callback call
provides the relevant details, like the element name. So at the startElement callback for <double> we know we’re
processing a <double> start-element.
That's the plan. We get to code the callbacks. We do it by writing a class that implements ContentHandler, or its subclass DefaultHandler which provides trivial implementations we can override.
See pg. 232, for the FibonacciHandler that implements the callbacks startElement, endElement, and characters to do our planned actions at the various events--
The characters method delivers text via an array of char, which gets printed out
The startElement and endElement methods turn on and off the inDouble flag. When the inDouble flag is set to true, the characters method prints the text.
Returning to the top-level of the client program in Example 5.3:
XMLReader parser = XMLReaderFactory.createXMLReader( ); // use no-args
constructor
creates the parser, when no argument is specified, it uses the default Xerces parser, which is the best
We have to tell this parser about the ContentHandler object, FibonacciHandler:
org.xml.sax.ContentHandler
handler
= new FibonacciHandler( );
// better import statement would make prefix unnecessary
parser.setContentHandler( handler );
Then a new InputSource object named "source" is created from the InputStream from the URLConnection to the server.
InputStream in = connection.getInputStream(
);
InputSource source = new InputSource(in);
// we don't have to specify the encoding of the input stream since the parser will
//determine the encoding from the XML document header
Then parser.parse(source) is called to do the parsing, creating the events, and thus the callbacks that are handled as planned.
// this call does not return until it finishes parsing the document and issuing the callbacks
Whitespace text in XML generates “extra”
calls to characters
Whitespace is text and a SAX parser will generate text events (callbacks to characters) for whitespace as well as character text. These calls are not shown above.
<?xml
version="1.0"?>
<methodResponse> <--in here have
<EOL><space><space><space> between element tags
<params>
Here the end-of-line <EOL> is <LF> on UNIX/Linux or <CR><LF> on Windows. So with the spaces we see 4 or 5 characters of whitespace between these two element tags. The whitespace in the above xml document is an example of "ignorable whitespace". This text can only be truly ignored by the parser if the document has a DTD. Without a DTD, we have to be ready for the parser to call characters to deliver each piece of whitespace between elements.
In a lot of cases we have to deal with this kind of whitespace in our programs, that is, tolerate calls to "characters" for these little bits of whitespace we don't care about.
The SAX parser descends this tree in a depth first, right to left traversal, generating events as it progresses
The XML tree here, showing the bits of whitespace between the tags:
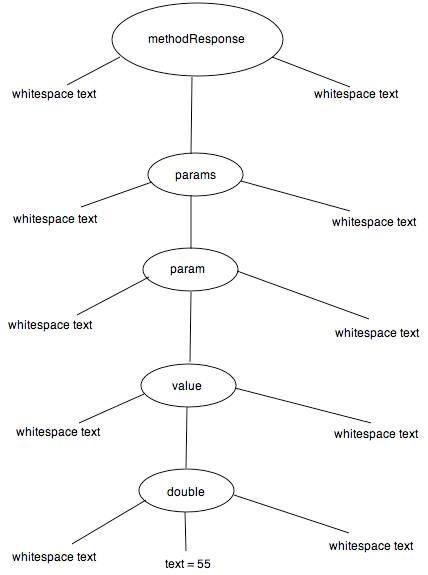
XML tree, showing bits of whitespace reported by SAX via calls to characters. In the example 5.3 program, these calls happen but most don’t produce output from the program because the flag “inDouble” is false, except at the bottom (which really shouldn’t have three separate text nodes).
Chapter 6
Ex 6.1 never turns on validation, so it is just checking well-formed-ness even with a validating parser and availability DTD/schema.
This program has useful error reports/diagnosis. It tells you the line no, column no and the problem. We should get back to how this works.
XMLReader is just an interface, see pg 877.
XMLReader parser = XMLReaderFactory.createXMLReader(); // factory method, a static method of XML Reader Factory, that return an object that IS-A XMLReader. (this object implements XMLReader).
Parser.parse(args[0]) // args[0] = “http:// www. …” New form of call to parse, with URL arg
Look at API, pg. 877 in the Appendix
Match this to--
parse(String systemID) // the systemID is the name of the URL document
vs. parse(InputSource input) which we have previously been using.
Note that both overloaded versions of parse throw IOException, SAXException.
Here the IOException is thrown by the parser code for I/O error it sees.
The SAXException can be thrown by the parser or by the callbacks (the parser calls the callbacks, like startElement).
Look at the catches in Ex. 6.1, how they report on the different exception cases.
DefaultHandler: convenience class, does not add any functionality. This provides do-nothing implementations for the 11 methods of content Handler + other trivial methods for other related interfaces.
The do-nothing implementation are of form void characters(..) throws SAXException {}; so our overriding methods can throw.
Compare the two ways to program the set of callbacks we need: use DefaultHandler, or implement ContentHandler directly:
Case 1: use DefaultHandler:
Ex. 6.5 – the class TextExtractor extends DefaultHandler { … } ß no do-nothing methods.
Case 2: implement ContestHandler directly:
Ex. 6.3 – the class TextExtractor implements ContentHandler{…} ßlots of do-nothing methods
Suggest use of DefaultHandler in pa2.
ContentHandler API
Pg 264 – ContentHandler’s core methods:
startElement() , endElement() and start/endDocument(), characters()
….
All these methods throw SAXException.
On the other hand, an overriding method can throw nothing, by Java rules, or a subclass of the overridden thrown class, like the method return value, which also can be a subclass of the original overridden return type.
Content Handler: provides access to the normal “meat” of the doc, not the way it’s expressed exactly in the XML doc. + no comments. The characters provide the text after CDATA markup taken out, character entities resolved & built-in entities.
- and provides little bits of whitespace we don’t really want.
The multiple document example, EX 6.6 is incomplete because it does not have a driver. The driver needs to have a try catch block around the call to parser.parse(), so one bad file name does not abort the entire process
Tracking the Element Hierarchy
when using SAX, needed for pa2 (some coverage in pa2.html)
When working with SAX, you have to track the element hierarchy yourself, you can't ask SAX what the parent of a given element is (unlike DOM)
In pa2 getting the full name of the method requires tracking the class hierarchy.
Given an xml document
We can find the path of any element using the following approach with a SAX parser:
startDocument: create a stack of type String
startElement: push the local name onto the stack ßand here get the path from the stack
endElement: pop the top String on the stack
endDocument: the stack should be empty
Example 6.7 uses this approach (ignore the JTree GUI)
Also, for pa2, note that TestXPath has ancestry-related code (climbs the DOM tree)
Handling Attributes in
SAX
Attributes are delivered with the startElement callback
SAX's startElement() has a parameter of type Attributes (pg. 279)
package org.xml.sax;
public interface Attributes
{
public int
getLength ();
public String getQName(int index);
public String getURI(int index);
public String getLocalName(int index);
public int getIndex(String uri, String localPart);
public int getIndex(String qualifiedName);
public String getType(String
uri, String localName);
public String getType(String
qualifiedName);
public String getType(int index);
public String getValue(String
uri, String localName); ß the one we want
public String getValue(String
qualifiedName);
public String getValue(int index);
}
This Attributes object contains a set of attributes of no particular order (an element has a set of attributes)
Still, individual attributes can be accessed by an index number in this representation, a somewhat surprising sytem.
We can use public String getValue(String uri, String localName) to search for the links we want. This is foolproof, since the URI is a unique id of the NS.