CS641 Class 9
Working on “Bigger Example” of Direct Mapped Cache:
16KB of data in a direct-mapped cache with 4 word blocks (32-bit machine)
° Offset
• block contains 4 words = 16 bytes = 24 bytes
• need 4 bits to specify correct byte in a block
• Index: (~index into an “array of blocks”)
• cache contains 16 KB = 214 bytes, block contains 24 bytes (4 words)
• # blocks/cache = 210, so need 10 bits to specify this many rows
• Tag: use remaining bits as tag
• tag length = addr length – offset - index = 32 - 4 - 10 bits = 18 bits
• so tag is leftmost 18 bits of memory address
Example A=
0x12345678
write in hex,
subdivide 000100100011010001|0101100111|1000
so index = 0101100111 =0x267,
offset = 1000
Check valid bit and
tag in entry 0x267 against tag here
If checks, get cache
block, here 4 words, 16 bytes, want bytes starting at 1000, i.e., half way
through the block
Else cache miss,
work harder
The whole picture (thanks to Ron Cheung’s slides)

Caching Terminology
° When we try to read memory, 3 things can happen
° cache hit: cache block is valid and contains proper address, so read desired word
° cache miss: nothing in cache in appropriate block, so fetch from memory
° cache miss, block replacement: wrong data is in cache at appropriate block, so discard it and fetch desired data from memory
MIPS architecture and memory access
° Processor requests:
• Instructions and data on every clock cycle
° Use separate 16kB instruction and data caches with 16-word blocks
° 16KB/(16*4) = 256 blocks/cache = 28, so 8 bits for index
° Offset contains 2 bits to select byte in word + 4 additional bits to select word within the block
° Leaves 18 bits for tag
Instruction cache: address from PC
Data cache: address from operand of instruction
Example: lb t1, 4($t0), itself at address 0x400128
Intrinsity FastMATH Cache for MIPS (pg. 469)

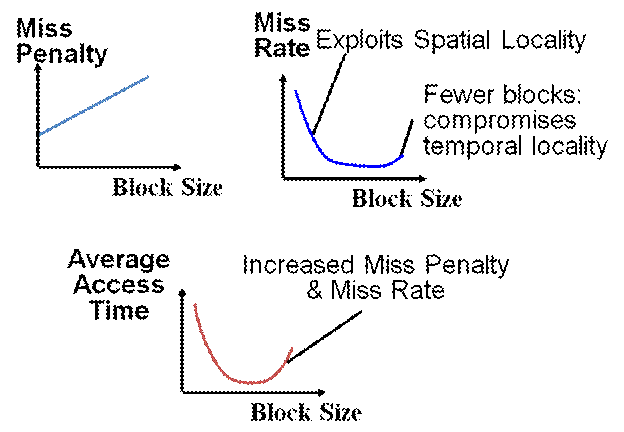
Block Size Tradeoff
° Benefits of Larger Block Size
• Spatial Locality: if we access a given word, we’re likely to access other nearby words soon
• Very applicable with Stored-Program Concept: if we execute a given instruction, it’s likely that we’ll execute the next few as well
• Works nicely in sequential array accesses too
Miss Rate vs. Block Size
° Miss rate goes up if block size is too large relative to the cache size: see graph, pg. 465.
° Drawbacks of Larger Block Size
• If block size is too big relative to cache size, then there are too few blocks
- Result: miss rate goes up
• Larger block size means larger miss penalty
- on a miss, takes longer time to load a new block from next level (more data to load)
Block Size Tradeoff Conclusions
Handling misses
° Option 1, processor stops, waits for the value
° Option 2, processor keeps going, waits at a use of the value: book, pg. 465, says we’re not covering this possibility
Handling writes
° Need to keep cache and memory consistent (the same)
° Could write into both cache and memory on a hit – called write through
° Every store in processor causes data to be written (10% of instructions are stores in SPEC2000 integer benchmarks)
° Write buffer – store data while waiting to write to memory, processor goes ahead
° Alternative is write-back- write to cache line, write memory only when line is needed.
Write buffer
° Processor stores data
° Copy data to write buffer, and cache
° Continue execution
° If a second store occurs and write buffer is full, stall
° If average rate of stores is < memory speed, then ok unless there is a burst, then need to stall
What to do on a write hit?
° Write-through
• update the word in cache block and corresponding word in memory
° Write-back
• update word in cache block only. Allow memory word to be “stale”
• => add ‘dirty’ bit to each line indicating that memory needs to be updated when block is replaced. OS flushes cache before I/O
Performance Tradeoffs
° Write back has less writes to memory
° needs less bandwidth – can be faster if memory is slower then processor
° Harder to implement
Designing the Memory System to Support Caches (pg. 471)
Traditional design:
CPU + cache <---memory bus---> Memory
Clock rate of the
memory bus significantly slower than clock rate of CPU: Ex 2G hz CPU, 400 Mhz
memory bus
Hypothetical setup, pg. 471:
· 1 memory bus cycle to send address
· 15 memory bus cycles to access DRAM
· 1 memory bus cycle to send a word of data
If memory is one word wide, we have to go through the memory controller separately for each access, to a 4-word cache line takes
1 + 4*15 + 4*1 = 65 mem cyc’s: 16 bytes in 65 cyc’s, or .25 bytes/cyc.
If memory and bus is two words wide, we only have 2 accesses:
1 + 2*15 + 2*1 = 33 mem cyc’s: 16 bytes in 33 cyc’s, or .48 bytes/cyc.: much better!
Wider bus is great, but expensive. Another approach is to organize the memory controllers into memory banks.
Address is sent to all 4 memory banks on pg. 472 at the same time, and they work in parallel to retrieve parts of the cache line.
--known as interleaving.
1 + 1*15 + 4*1 = 20, 16 bytes in 20 cyc’s = .80 bytes/cyc.,
even better.
5.3 Cache Performance
Idea of CPU time for
a program:
A typical program runs for a while, then waits for input or output, runs again for a while, and so on. When it waits for i/o, it is not using CPU time. Instead, the OS gets involved (it was already involved because of the i/o), and reschedules this program and runs something else for a while, until this program is ready to run again.
So CPU time <= elapsed time for a program running on a single core, and usually quite a bit less. With multiple cores, we need to look at each and see this situation.
CPU time breakdown
Now we zoom in on the time the program is running on a certain core. Although wait for i/o is not lost time because the OS reschedules, the wait time to access memory on a cache miss is lost. It’s too short a time to be recovered by rescheduling, which itself takes a microsecond or so. The OS is not involved at all in the operation of a cache miss if the data is in main memory. (It does get involved if a disk access is needed, but that’s a different subject.)
We see it’s all up to the CPU to manage the bus and access to main memory. Here’s the breakdown:
° CPU time = (CPU exec clock cycles + memory stall cycles) * clock cycle time
° Memory stalls = read stalls + write stalls
° --to be continued next time